
The development and progress of language models in the past few years have marked their presence almost everywhere, not only in NLP research but also in commercial offerings and real-world applications. However, the surge in commercial demand for language models has, to a certain extent, hindered the growth of the community. This is because a majority of state-of-the-art and capable models are gated behind proprietary interfaces, making it impossible for the development community to access vital details of their training architecture, data, and development processes. It is now undeniable that these training and structural details are crucial for research studies, including access to their potential risks and biases, thus creating a requirement for the research community to have access to a truly open and powerful language model.
To meet this requirement, developers have created OLMo, a state-of-the-art, truly open language model framework. This framework allows researchers to use OLMo to build and study language models. Unlike most state-of-the-art language models, which have only released interface code and model weights, the OLMo framework is truly open source, with publicly accessible evaluation code, training methods, and training data. OLMo’s primary aim is to empower and boost the open research community and the continuous development of language models.
In this article, we will discuss the OLMo framework in detail, examining its architecture, methodology, and performance compared to current state-of-the-art frameworks. So, let’s get started.
OLMo: Enhancing the Science of Language Models
The language model has arguably been the hottest trend for the past few years, not only within the AI and ML community but also across the tech industry, due to its remarkable capabilities in performing real-world tasks with human-like performance. ChatGPT is a prime example of the potential language models hold, with major players in the tech industry exploring language model integration with their products.
NLP, or Natural Language Processing, is one of the industries that has extensively employed language models over the past few years. However, ever since the industry started employing human annotation for alignment and large-scale pre-training, language models have witnessed a rapid enhancement in their commercial viability, resulting in a majority of state-of-the-art language and NLP frameworks having restricted proprietary interfaces, with the development community having no access to vital details.
To ensure the progress of language models, OLMo, a state-of-the-art, truly open language model, offers developers a framework to build, study, and advance the development of language models. It also provides researchers with access to its training and evaluation code, training methodology, training data, training logs, and intermediate model checkpoints. Existing state-of-the-art models have varying degrees of openness, whereas the OLMo model has released the entire framework, from training to data to evaluation tools, thus narrowing the performance gap when compared to state-of-the-art models like the LLaMA2 model.
For modeling and training, the OLMo framework includes the training code, full model weights, ablations, training logs, and training metrics in the form of interface code, as well as Weights & Biases logs. For analysis and dataset building, the OLMo framework includes the full training data used for AI2’s Dolma and WIMBD models, along with the code that produces the training data. For evaluation purposes, the OLMo framework includes AI2’s Catwalk model for downstream evaluation, and the Paloma model for perplexity-based evaluation.
OLMo : Model and Architecture
The OLMo model adopts a decoder-only transformer architecture based on the Neural Information Processing Systems, and delivers two models with 1 billion and 7 billion parameters respectively, with a 65 billion parameter model currently under development.
The architecture of the OLMo framework delivers several improvements over frameworks including the vanilla transformer component in their architecture including recent state of the art large language models like OpenLM, Falcon, LLaMA, and PaLM. The following figure compares the OLMo model with 7B billion parameters against recent LLMs operating on almost equal numbers of parameters.

The OLMo framework selects the hyperparameters by optimizing the model for training throughput on the hardware while at the same time minimizing the risk of slow divergence and loss spikes. With that being said, the primary changes implemented by the OLMo framework that distinguishes itself from the vanilla transformer architecture are as follows:
No Biases
Unlike Falcon, PaLM, LLaMA and other language models, the OLMo framework does not include any bias in its architecture to enhance the training stability.
Non-Parametric Layer Norm
The OLMo framework implements the non-parametric formulation of the layer norm in its architecture. The Non-Parametric Layer Norm offers no affine transformation within the norm i.e it does not offer any adaptive gain or bias. Non-Parametric Layer Norm not only offers more security that Parametric Layer Norms, but they are also faster.
SwiGLU Activation Function
Like a majority of language models like PaLM and LLaMA, the OLMo framework includes the SwiGLU activation function in its architecture instead of the ReLU activation function, and increases the hidden activation size to the closest multiple of 128 to improve throughput.
RoPE or Rotary Positional Embeddings
The OLMo models follow the LLaMA and PaLM models and swap the absolute positional embeddings for RoPE or Rotary Positional Embeddings.
Pre Training with Dolma
Although the development community now has enhanced access to model parameters, the doors to access pre-training datasets still remain shut as the pre-training data is not released alongside the closed models nor alongside the open models. Furthermore, technical documentations covering such data often lack vital details required to fully understand and replicate the model. The roadblock makes it difficult to carry forward the research in certain threads of language model research including the understanding of how the training data impacts the capabilities and limitations of the model. The OLMo framework built and released its pre-training dataset, Dolma, to facilitate open research on language model pre-training. The Dolma dataset is a multi-source and diverse collection of over 3 trillion tokens across 5 billion documents collected from 7 different sources that are commonly used by powerful large-scale LLMs for pre-training and are accessible to the general audience. The composition of the Dolma dataset is summarized in the following table.
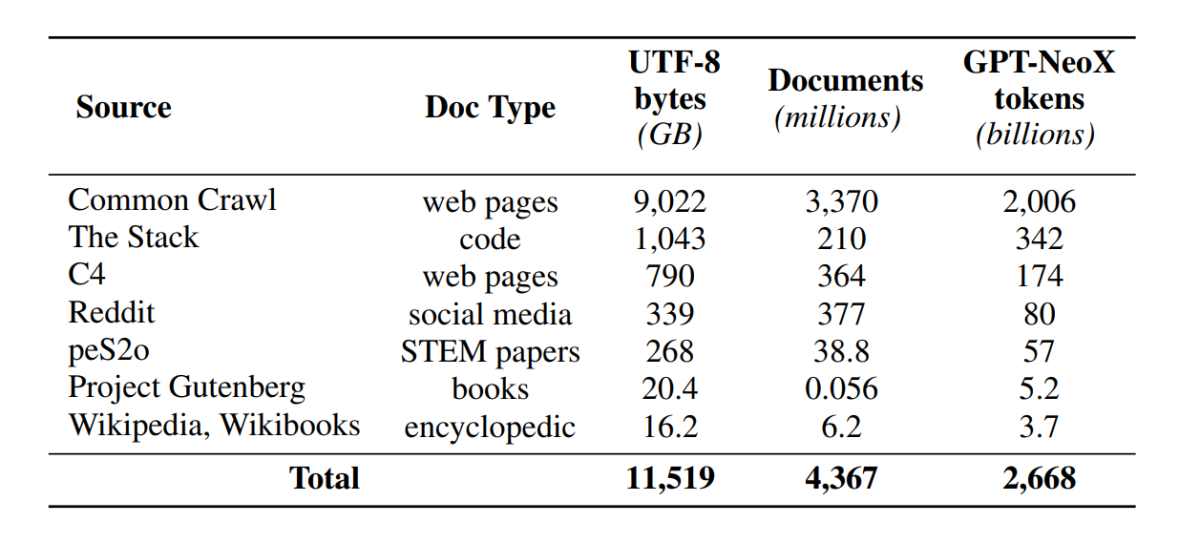
The Dolma dataset is built using a pipeline of 5 components: language filtering, quality filtering, content filtering, multi-source mixing, deduplication, and tokenization. OLMo has also released the Dolma report that provides more insights into the design principles and construction details along with a more detailed content summary. The model also open sources its high performance data curation tools to enable easy and quick curation of pre-training data corpora. Evaluation of the model follows a two-staged strategy, starting with online evaluation for decision-making during model training and a final offline evaluation for an aggregated evaluation from model checkpoints. For offline evaluation, OLMo uses the Catwalk framework, our publicly available evaluation tool that has access to a broad diversity of datasets and task formats. The framework uses Catwalk for downstream evaluation as well as intrinsic language modeling evaluation on our new perplexity benchmark, Paloma. OLMo then compares it against several public models using its fixed evaluation pipeline, for both downstream and perplexity evaluation.
OLMo runs several evaluation metrics about the model architecture, initialization, optimizers, learning rate schedule, and mixtures of data during the training of the model. Developers call it OLMo’s “online evaluation” in that it’s an in-loop iteration at every 1000 training steps (or ∼4B training tokens) to give an early and continuous signal on the quality of the model being trained. The setup of these evaluations depends on a majority of core tasks and experiment settings used for our offline evaluation. OLMo aims for not just comparisons of OLMo-7B against other models for best performance but also to show how it enables fuller and more controlled scientific evaluation. OLMo-7B is the biggest Language Model with explicit decontamination for perplexity evaluation.
OLMo Training
It’s important to note that the OLMo framework models are trained using the ZeRO optimizer strategy, which is provided by the FSDP framework through PyTorch and, in this way, substantially reduces GPU memory consumption by sharding model weights over GPUs. With this, at the 7B scale, training can be done with a micro-batch size of 4096 tokens per GPU on our hardware. The training framework for OLMo-1B and -7B models uses a globally constant batch size of about 4M tokens (2048 instances each with a sequence length of 2048 tokens). For the model OLMo-65B (currently in training), developers use a batch size warmup that starts at about 2M tokens (1024 instances), doubling every 100B tokens until about 16M tokens (8192 instances).
To improve throughput, we employ mixed-precision training (Micikevicius et al., 2017) through FSDP’s built-in settings and PyTorch’s amp module. The latter ensures that certain operations like the softmax always run in full precision to improve stability, while all other operations run in half-precision with the bfloat16 format. Under our specific settings, the sharded model weights and optimizer state local to each GPU are kept in full precision. The weights within each transformer block are only cast to bfloat16 format when the full-sized parameters are materialized on each GPU during the forward and backward passes. Gradients are reduced across GPUs in full precision.
Optimizer
The OLMo framework makes use of the AdamW optimizer with the following hyperparameters.

For all model sizes, the learning rate warms up linearly over the first 5000 steps (∼21B tokens) to a maximum value, and then decays linearly with the inverse square root of the step number to the specified minimum learning rate. After the warm-up period, the model clips gradients such that the total l-norm of the parameter gradients does not exceed 1.0. The following table gives a comparison of our optimizer settings at the 7B scale with those from other recent LMs that also used AdamW.

Training Data
Training involves tokenizing training instances by word and BPE tokenizer for the sentence piece model after adding a special EOS token at the end of each document, and then we group consecutive chunks of 2048 tokens to form training instances. Training instances are shuffled in the exact same way for each training run. The data order and exact composition of each training batch can be reconstructed from the artifacts we release. All of the released OLMo models have been trained to at least 2T tokens (a single epoch over its training data), and some were trained beyond that by starting a second epoch over the data with a different shuffling order. Given the small amount of data that this repeats, it should have a negligible effect.
Results
The checkpoint used for evaluation of OLMo-7B is trained up to 2.46T tokens on the Dolma data set with the linear learning rate decay schedule mentioned before. Further tuning this checkpoint on the Dolma dataset for 1000 steps with linearly decayed learning rate to 0 further increases model performance on perplexity and end-task evaluation suites described before. For the final evaluation, developers compared OLMo with other publicly available models – LLaMA-7B, LLaMA2-7B, Pythia-6.9B, Falcon-7B and RPJ-INCITE-7B.
Downstream evaluation
The core downstream evaluation suite is summarized in the following table.
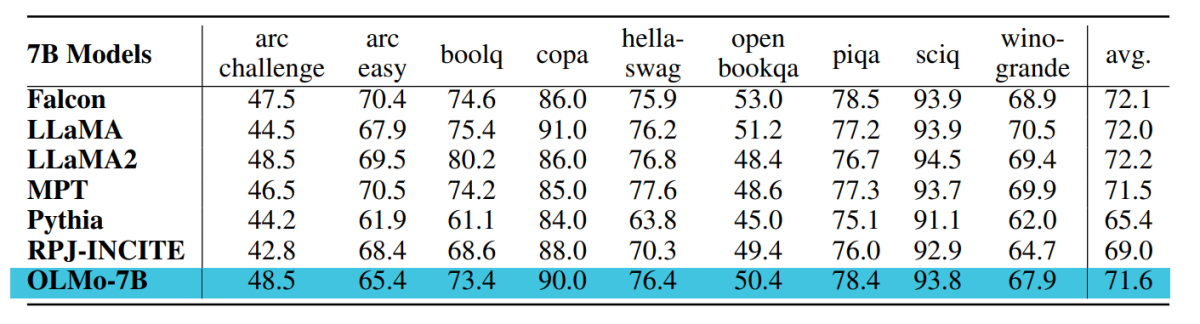
We conduct zero-shot evaluation by rank classification approach in all cases. In this approach, the candidate text completions (e.g., different multiple-choice options) are ranked by likelihood (usually normalized by some normalization factor), and prediction accuracy is reported.
While Catwalk uses several typical likelihood normalization methods, such as per token normalization and per-character normalization, the normalization strategies applied are chosen separately for each dataset and include the answer’s unconditional likelihood. More concretely, this involved no normalization for the arc and openbookqa tasks, per-token normalization for hellaswag, piqa, and winogrande tasks, and no normalization for boolq, copa, and sciq tasks (i.e., tasks in a formulation close to a single token prediction task).

The following figure shows the progress of accuracy score for the nine core end-tasks. It can be deduced that there is a generally increasing trend in the accuracy number for all tasks, except for OBQA, as OLMo-7B is further trained on more tokens. A sharp upward tick in accuracy of many tasks between the last and second to last step shows us the benefit of linearly reducing the LR to 0 over the final 1000 training steps. For instance, in the case of intrinsic evaluations, Paloma argues through a series of analyses, from the inspection of performance in each domain separately up to more summarized results over combinations of domains. We report results at two levels of granularity: the aggregate performance over 11 of the 18 sources in Paloma, as well as more fine-grained results over each of these sources individually.

Final Thoughts
In this article, we have talked about OLMo, a state of the art truly open language model offers developers a framework to build, study, and advance the development of language models along with providing researchers access to its training and evaluation code, training methodology, training data, training logs, and intermediate model checkpoints. Existing state of the art models have varying degrees of openness whereas the OLMo model has released the entire framework from training to data to evaluation tools, thus narrowing the gap in performance when compared against state of the art models like LLaMA2 model.


Credit: Source link