
The ability to accurately interpret complex visual information is a crucial focus of multimodal large language models (MLLMs). Recent work shows that enhanced visual perception significantly reduces hallucinations and improves performance on resolution-sensitive tasks, such as optical character recognition and document analysis. Several recent MLLMs achieve this by utilizing a mixture of vision encoders. Despite their success, there is a lack of systematic comparisons and detailed ablation studies addressing critical aspects, such as expert selection and the integration of multiple vision experts. This article provides an extensive exploration of the design space for MLLMs using a mixture of vision encoders and resolutions, the Eagle framework that attempts to explore the design space for multimodal large language models with a mixture of encoders. The findings reveal several underlying principles common to various existing strategies, leading to a streamlined yet effective design approach. Eagle discovers that simply concatenating visual tokens from a set of complementary vision encoders is as effective as more complex mixing architectures or strategies. Additionally, Eagle introduces Pre-Alignment to bridge the gap between vision-focused encoders and language tokens, enhancing model coherence. The resulting family of MLLMs, Eagle, surpasses other leading open-source models on major MLLM benchmarks.
Eagle’s work is related to the general architecture design of multimodal large language models (MLLMs). Besides the line of representative open-source research mentioned earlier, other notable families of MLLMs include, but are not limited to, MiniGPT-4, Lynx, Otter, QwenVL, CogVLM, VILA, GPT-4V, Gemini, and Llama 3.1. Depending on how vision signals are integrated into the language model, MLLMs can be broadly categorized into “cross-modal attention” models and “prefix-tuning” models. The former injects visual information into different layers of LLMs using cross-modal attention, whereas the latter treats the visual tokens as part of the language token sequence and directly appends them with text embeddings. Eagle’s model belongs to the prefix-tuning family by following a LLaVA-styled multimodal architecture. Considering that MLLM is a fast-growing field, Eagle recommends referring to more detailed studies and surveys for further insights.
Eagle’s work is closely related to research focused on improving vision encoder designs for MLLMs. Early works usually adopted vision encoders pre-trained on vision-language alignment tasks such as CLIP and EVA-CLIP. Stronger vision encoders, such as SigLIP and InternVL, have been proposed to enhance vision-language tasks with better designs, larger model sizes, and more effective training recipes. Since models are often pre-trained on low-resolution images and may lack the ability to encode fine-grained details, higher resolution adaptation is frequently performed to increase the MLLM input resolution. In addition to higher resolution adaptation, models like LLaVA-NeXT, LLaVA-UHD, Monkey, InternLM-XComposer, and InternVL use tiling or adaptive tiling to handle high-resolution input, where images are divided into lower-resolution patches and processed separately. While the ability to handle higher resolution is made possible by introducing additional vision experts, this approach differs slightly from tiling techniques, though both are compatible and can be combined.
The success of large language models (LLMs) has sparked significant interest in enabling their visual perception capabilities, allowing them to see, understand, and reason in the real world. At the core of these multimodal large language models (MLLMs) is a typical design where images are converted into a series of visual tokens by the vision encoders and appended with the text embeddings. CLIP is often chosen as the vision encoder because its visual representation is aligned with the text space by pre-training on image-text pairs. Depending on the architectures, training recipes, and the way vision tokens are injected into the language model, notable families of MLLMs include Flamingo, BLIP, PaLI, PaLM-E, and LLaVA. Most of these models maintain relatively low input resolutions due to limitations in pre-trained vision encoders and LLM sequence length. Eagle’s work is closely aligned with models that use multiple vision encoders for improved perception. Mini-Gemini and LLaVA-HR propose fusing high-resolution visual features into low-resolution visual tokens. Beyond resolution issues, these pre-trained vision encoders may lack specific capabilities such as reading text or localizing objects. To address this, various models integrate vision encoders pre-trained on different vision tasks to enhance the vision encoder’s capabilities.
For instance, models like Mousi and Brave fuse visual tokens from different vision encoders by concatenating along the channel or token direction. RADIO introduces a multi-teacher distillation method to unify the abilities of different vision encoders into a single model. MoAI, IVE, and Prismer further use the output of vision experts, such as OCR, detection, or depth estimation, to supplement additional information for MLLMs to generate answers. MoVA devises a routing network to assign an optimal vision model based on the given image and instructions.
Recent studies have shown that stronger vision encoder designs are important for reducing MLLM hallucinations and improving performance on resolution-sensitive tasks like optical character recognition (OCR). Several works focus on enhancing the capability of the vision encoder, either by scaling up the pre-training data and parameters or by dividing images into low-resolution patches. However, these approaches often introduce large training resource demands. An efficient yet powerful strategy is mixing visual encoders pre-trained with different tasks and input resolutions, either by fusing higher resolution encoders with the CLIP encoder, sequentially appending features from different encoders, or adopting more complex fusion and routing strategies to maximize the benefits of different encoders. This “mixture-of-vision-experts” approach has proven effective, though a detailed study of its design space with rigorous ablation is still lacking, motivating Eagle to revisit this area. Key questions remain: which vision encoder combinations to choose, how to fuse different experts, and how to adjust training strategies with more vision encoders.
To address these questions, Eagle systematically investigates the mixture-of-vision-encoders design space for improved MLLM perception. The exploration of this design space involves the following steps: 1) Benchmarking various vision encoders and searching for higher resolution adaptation; 2) Conducting an “apples to apples” comparison between vision encoder fusion strategies; 3) Progressively identifying the optimal combination of multiple vision encoders; 4) Improving vision expert pre-alignment and data mixture. The exploration steps are illustrated in the following image.
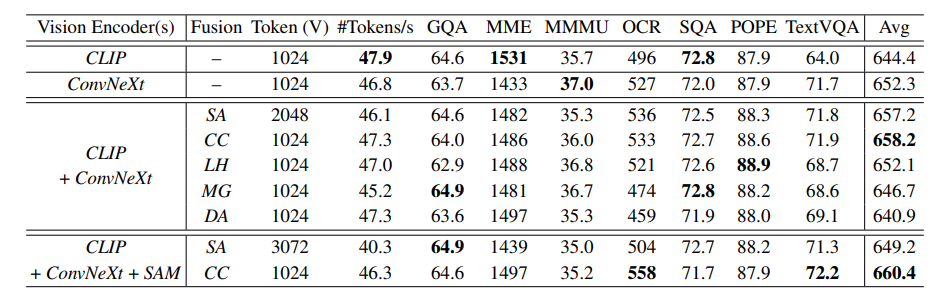
Eagle’s study covers the performance of vision encoders pre-trained on different tasks and resolutions, such as vision-language alignment, self-supervised learning, detection, segmentation, and OCR. Using a round-robin approach, Eagle begins with the basic CLIP encoder and adds one additional expert at a time, selecting the expert that provides the best improvement in each round.
While Eagle’s work is not the first to leverage multiple vision encoders in MLLMs, the systematic study leads to several key findings under this setting:
- Unlocking the vision encoders during MLLM training matters. This is in contrast to models like LLaVA and others that consider multiple vision encoders or teachers, where freezing the vision encoders has been common practice.
- Some recently proposed fusion strategies do not show significant advantages. Instead, straightforward channel concatenation emerges as a simple yet competitive fusion strategy, offering the best efficiency and performance.
- Incorporating additional vision experts leads to consistent gains. This makes it a promising path for systematically enhancing MLLM perception, aside from scaling up single encoders. The improvement is particularly pronounced when vision encoders are unlocked.
- Pre-alignment stage is key. Eagle introduces a pre-alignment stage where non-text-aligned vision experts are individually fine-tuned with a frozen LLM before being trained together. This stage significantly enhances MLLM performance under the mixture-of-vision-encoder design.
Eagle: Methodology and Architecture
Unlike previous methods that focus on new fusion strategies or architectures among vision encoders, Eagle’s goal is to identify a minimalistic design to fuse different vision encoders, supported by detailed ablations and removing any unnecessary components. As shown in the following figure, Eagle starts by extending the basic CLIP encoder to a set of vision experts with different architectures, pre-training tasks, and resolutions. With these experts, Eagle then compares different fusion architectures and methods and explores how to optimize pre-training strategies with multiple encoders.

Finally, Eagle combines all the findings and extends the approach to multiple expert vision encoders with varying resolutions and domain knowledge. Using the same pre-training data as LLaVA-1.5, which consists of 595k image-text pairs, Eagle moves to the supervised fine-tuning stage by collecting data from a series of tasks and converting them into multimodal conversations, including LLaVA-1.5, Laion-GPT4V, ShareGPT-4V, DocVQA, synDog-EN, ChartQA, DVQA, and AI2D, resulting in 934k samples.
The model is first pre-trained with image-text pairs for one epoch with a batch size of 256, where the entire model is frozen, and only the projector layer is updated. In the second stage, the model is fine-tuned on the supervised fine-tuning data for one epoch with a batch size of 128. For this exploration, Eagle employs Vicuna-7B as the underlying language model. The learning rates are set to 1e-3 for the first stage and 2e-5 for the second stage.
Stronger CLIP Encoder
Eagle begins the exploration with the CLIP model, as it has become the primary choice for many MLLMs. While CLIP models are known to enhance multimodal tasks, their limitations have also been well-documented. For example, many existing MLLMs tend to use the pre-trained CLIP resolutions (such as 224 × 224 or 336 × 336) as their input resolutions. In these cases, the encoders often struggle to capture fine-grained details important for resolution-sensitive tasks like OCR and document understanding.
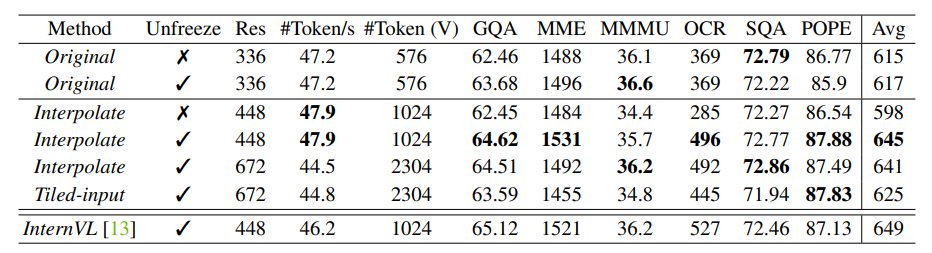
To handle increased input resolution, a common approach is tiling, where input images are divided into tiles and encoded separately. Another simpler method is to directly scale up the input resolution and interpolate the position embeddings of the vision transformer model if necessary. Eagle compares these two approaches with frozen and unfrozen vision encoders across different resolutions, with the results contained in the above table. The findings can be summarized as follows:
- Unfreezing the CLIP encoder leads to significant improvement when interpolating to a higher MLLM input resolution that differs from the CLIP pre-training resolution, without performance degradation when resolutions remain the same.
- Freezing the CLIP encoder and directly adapting it to a higher MLLM input resolution significantly harms performance.
- Among the strategies compared, directly interpolating to 448 × 448 with an unfrozen CLIP encoder proves to be both effective and efficient in terms of performance and cost.
- The best CLIP encoder achieves performance close to InternVL, despite being a much smaller model (300M vs. 6B) with less pre-training data.
It is worth noting that CLIP-448 allows Eagle to match the setting with LLaVA-HR and InternVL, where the CLIP encoders are similarly adapted to take 448 × 448 input and output 1024 patch tokens. For further investigation, Eagle follows this simple strategy of scaling up the input resolution and unlocking the vision encoder during training.

Eagle observes that existing popular fusion strategies, despite their design variations, can be broadly categorized as follows:
- Sequence Append: Directly appending the visual tokens from different backbones as a longer sequence.
- Channel Concatenation: Concatenating the visual tokens along the channel dimension without increasing the sequence length.
- LLaVA-HR: Injecting high-resolution features into low-resolution vision encoders using a mixture-of-resolution adapter.
- Mini-Gemini: Using the CLIP tokens as low-resolution queries to cross-attend another high-resolution vision encoder in co-located local windows.
- Deformable Attention: A new baseline introduced on top of Mini-Gemini, where the vanilla window attention is replaced with deformable attention.
Instead of training a projector to simultaneously align multiple vision experts as in LLaVA’s original pre-training strategy, we first align the representation of each individual expert with a smaller language model (Vicuna-7B in practice) using next-token-prediction supervision. As shown in the figure below, with pre-alignment, the whole training process consists of three steps: 1) training each pre-trained vision expert with their own projector on SFT data, while keeping the language model frozen; 2) combining all the vision experts from the first step and training only the projector with image-text pairs data; 3) training the whole model on the SFT data.

Eagle: Experiments and Results
After meticulously developing its strategies, Eagle has established the following principles for the model: (1) integrating more vision experts with an optimized training recipe; (2) combining multiple vision experts through direct channel concatenation; (3) pre-training the vision experts separately via pre-alignment. In this section, to further demonstrate the advantages of the Eagle models, additional training data is incorporated, and Eagle is compared against the current state-of-the-art MLLMs across various tasks. Eagle uses Vicuna-v1.5-7B, Llama3-8B, and Vicuna-v1.5-13B as the language models. For the vision encoders, based on the results in Section 2.6, Eagle models are denoted as Eagle-X4, which includes four vision encoders: CLIP, ConvNeXt, Pix2Struct, and EVA-02, and Eagle-X5, which includes an additional SAM vision encoder.
Visual Question Answering Tasks
Eagle compares the model series across three Visual Question Answering (VQA) benchmarks, including GQA, VQAv2, and VizWiz. As shown in the following table, Eagle-X5 achieves state-of-the-art performance on GQA and VQAv2, highlighting the advantages of incorporating additional vision experts.

OCR and Chart Understanding Tasks
To evaluate the OCR, document, and chart understanding capabilities of Eagle, the model is benchmarked on OCRBench, TextVQA, and ChartQA. As shown in the above table, Eagle significantly surpasses competitors on TextVQA, benefiting from its high-resolution architecture and integration of different vision encoders. Notably, Eagle maintains a straightforward design, supporting up to 1024 tokens without requiring complex tile decomposition of images.
The figure below presents examples of OCR and document understanding cases. With high-resolution adaptation and the inclusion of more vision experts, Eagle can identify small text within images and accurately extract information based on user instructions.

To better understand the benefits of introducing experts pre-trained on other vision tasks, the following figure visualizes results from a model with only the ConvNeXt and CLIP vision encoders, compared to the results of Eagle-X5. With the full set of vision encoders, the model successfully corrects mistakes, demonstrating that even when equipped with high-resolution vision encoders pre-trained on vision-language alignment, Eagle’s capabilities are further enhanced by integrating additional vision experts pre-trained on diverse vision tasks.

Multimodal Benchmark Evaluation
Eagle is evaluated on seven benchmarks for MLLMs to demonstrate its capabilities from different perspectives, including MME, MMBench, SEED, MathVista, MMMU, ScienceQA, and POPE. Specifically, MME, MMBench, and SEED assess the overall performance on various real-world tasks involving reasoning, recognition, knowledge, and OCR. MMMU focuses on challenging problems from diverse domains that require college-level knowledge. POPE evaluates the visual hallucinations of MLLMs. The metrics used in this evaluation adhere to the default settings of these benchmarks. Eagle reports the perception score for MME, the en_dev split for MMBench, the image split of SEED, the test-mini split of MathVista, the val split of MMMU, the F1-score of POPE, and the image score for ScienceQA, ensuring alignment with the reported scores from other models.

Final Thoughts
In this article, we have talked about Eagle, an in-depth analysis of the design space for integrating vision encoders into multimodal large language models. Unlike previous works that focus on designing novel fusion paradigms, Eagle finds that systematic design choices matter and discovers a series of useful techniques. Step by step, Eagle optimizes the training recipe of individual vision encoders, identifies an extendable and efficient fusion method, and gradually combines vision encoders with different domain knowledge. The results highlight the critical importance of basic design space considerations.


Credit: Source link